 iempre me han interesado las cuantificaciones para estudiar situaciones y procesos que no pueden apreciarse sino mediante el estudio de regularidades y patrones colectivos. Una de las vías más interesantes es el seguimiento de términos y conceptos, porque evidentemente toda nueva realidad debe de ser pensada y nombrada. En este sentido, el masivo «corpus» de Google Libros es una excelente fuente, porque permite una búsqueda en el tiempo para apreciar cuando un término (por ejemplo, «despotismo ilustrado») comenzó a ser de uso común. La compilación y procesamiento cuantitativo de registros de este género es también de interés serial porque hace posible ver la aparición, desarrollo y posible declive del empleo de términos en el tiempo. Se le conoce como «minería de textos», una metáfora que me agrada por sus alusiones metalúrgicas. Es incluso un posible campo de estudios en sí, llamado provisionalmente culturomics (o, muy feamente en español, «culturomía»).
iempre me han interesado las cuantificaciones para estudiar situaciones y procesos que no pueden apreciarse sino mediante el estudio de regularidades y patrones colectivos. Una de las vías más interesantes es el seguimiento de términos y conceptos, porque evidentemente toda nueva realidad debe de ser pensada y nombrada. En este sentido, el masivo «corpus» de Google Libros es una excelente fuente, porque permite una búsqueda en el tiempo para apreciar cuando un término (por ejemplo, «despotismo ilustrado») comenzó a ser de uso común. La compilación y procesamiento cuantitativo de registros de este género es también de interés serial porque hace posible ver la aparición, desarrollo y posible declive del empleo de términos en el tiempo. Se le conoce como «minería de textos», una metáfora que me agrada por sus alusiones metalúrgicas. Es incluso un posible campo de estudios en sí, llamado provisionalmente culturomics (o, muy feamente en español, «culturomía»).
La herramienta más a propósito para estos fines son los n-gramas, esto es la búsqueda de secuencias o «cadenas» de información, en este caso en un texto (hay otros empleos posibles). Desde luego, hacerlo «a mano» es muy laborioso, pero afortunadamente Google ofrece gratuitamente y en línea su Ngram Viewer, que permite hacer búsquedas que generan automáticamente gráficas muy presentables. Es como hacer un verso sin ningún esfuerzo.
Caben algunas advertencias (como siempre debe hacerse con cualquier estadística) antes de confiar alegremente en los resultados. Aunque podría pensarse que Google Libros representa el universo de todos los impresos, esto no es exactamente así. Sus ejemplares digitalizados provienen de bibliotecas públicas de prestigio, esto es de repositorios que adquieren y almacenan los libros considerados «de interés», lo cual establece un filtro de entrada. Las obras que se venden en puestos callejeros, los comics, muchos «bestsellers» (¿en cuántas bibliotecas universitarias estará la «saga» completa de Harry Potter?) probablemente estén subrepresentados; lo que tenemos aquí sería una compilación primordialmente de literatura «culta» y «académica».
Asimismo, ya he comprobado que el escaneo de Google tiende a confundirse con las letras impresas de libros muy antiguos. Para tiempos modernos, también puede haber algunos casos de homonimias y «falsos positivos». Ah, y las búsquedas deben hacerse separando las variables por comas, no entrecomilladas.
Finalmente, este «visor» hace las búsquedas por corpus lingüísticos particulares; no está del todo «al día» en la indexación (en español llega sólo hasta 2008); y en su vertiente «automática» sólo incluye cadenas de alta frecuencia (esto es, que aparecen al menos en 40 libros distintos). Hay por otro lado opciones para «afinar» las búsquedas con algunos descriptores avanzados, que se explican aquí; y es posible consultar los datos «en bruto», si se tienen aficiones «culturómicas» y se cuenta con una conexión a red muy eficiente.
Con todas estas precauciones, el N-gram Viewer es interesante y atractivo. Para no alargarme, dejaré los experimentos para otra nota que publicaré en breve en este blog. Por lo pronto, les dejo un ejemplo sobre las n-gramas cruzadas de las menciones en español a dos autores de importante influencia en humanidades y ciencias sociales.
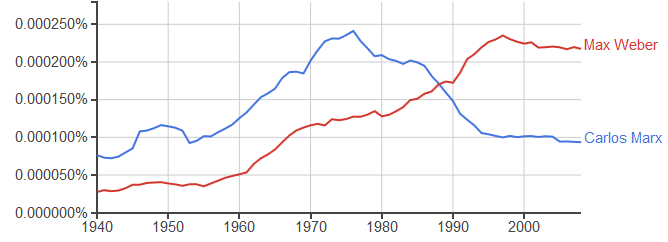
Los porcentajes corresponden a las frecuencias respecto del conjunto de textos.
Vale la pena señalar que el empleo de esta herramienta digital parece estar siendo progresivamente aceptada en publicaciones académicas formales, aunque ha sido también motivo de diversas objeciones. Y, desde luego, son gráficas que admiten distintas interpretaciones, porque las cifras en sí siempre serán solamente un punto de partida para la reflexión.

Una herramienta ciertamente interesante aunque, como bien adviertes, hay que tomarse los resultados con muchas reservas. Y yendo un poco más allá, cabría entrar en la discusión sobre si son realmente útiles para el trabajo de investigación más profundo. Al criticar las «falacias epistemológicas» de muchos de los trabajos de investigación que se inscriben en eso que ahora llaman Digital History, Johanna Drucker (UCLA) ha dicho que este tipo de herramientas son «just to crude for humanistic work» ya que estos programas carecen de transparencia que permita evaluar la manera en la que se decidió establecer los parámetros de búsqueda al generar «standard diagrams based on conventional algorithms for screen display… mak[ing] it very difficult for semantics of the data processing to be made evident.»
Se puede consultar la crítica de Drucker en el video de su lectura: «Should Humanist Visualize Knowledge?» en la siguiente dirección: https://vimeo.com/140307034
[…] * Ver el Blog de Felipe Castro: https://cliotropos.wordpress.com/2016/02/10/explorando-tendencias/ […]
Muy buen artículo y, en particular, considero que es muy pertinente tu reflexión en torno al proceso de discriminación que realiza Google Libros con los materiales que presenta. Algunos creen, particularmente los estudiantes de licenciatura, que se trata de un reservorio donde se puede hallar todo tipo de materiales. ¡Felicidades!